抽出したデータを見て、「同じ名前や項目が何度も出てきて邪魔だな」と感じたことはありませんか?
Excelなら「重複の削除」ボタンを押す作業ですが、SQLではDISTINCT(ディスティンクト)という命令1つで、重複のない「ユニークな(唯一の)データ」を作成できます。
1.DISTINCTの基本
DISTINCTは、表示したいカラムの直前に記述します。
SELECT
DISTINCT カラム名
FROM
テーブル名;2.実際に使ってみよう
例えば、顧客が住んでいる「地域の種類」を一覧にしたいとします。
まずは、customers テーブルから prefecture(顧客の居住地域)をそのまま出力してみましょう。
SELECT
prefecture
FROM
`test.customers`;実行すると、グリーン枠のように『東京都』が重複して表示されます。
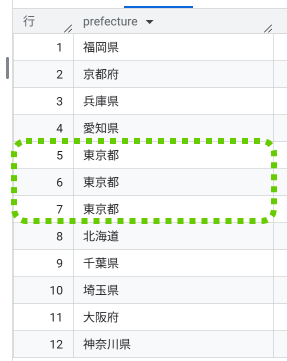
これでは、結局「何種類の地域があるのか」を把握するには不便ですよね。
ここで、重複を解消するために DISTINCTを使用します。
SELECT
DISTINCT prefecture
FROM
`test.customers`;先ほどまで3つ存在していた『東京都』が、1つに集約されました。
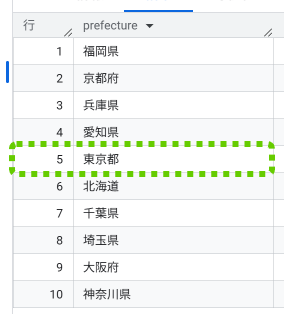
これは、DISTINCTが指定したカラムをスキャンし、同一データを除外して「ユニークな(重複のない)値」だけを抽出したからです。
3.まとめ
お疲れさまでした!
DISTINCTをマスターすれば、膨大な生データから「結局、何種類あるのか?」を瞬時に把握できるようになります。
データがスッキリ整理されると、その後の抽出・集計がずっと楽になります。
